The blog is on recognizing handwritten digits(0 to 9) from the given datasets.Recognizing handwritten makes computer more user friendly .We can use machine learning to recognize the hand written digits.The scikit-learn library (http://scikit-learn.org/) enables you to approach this type of data analysis.
The problem we have to face in type of project involves predicting a numeric value and then reading and interpreting an image that uses a handwritten font.So even this case we have an estimator with the task of learning through a fit( ) function, and once it has reached a degree of predictive capability(a model sufficiently valid),it will produce a prediction with the predict( ) function.Then we will discuss the training set and validation set,created this time form a series of images.
Importing Python libraries:

Reading information about Datasets using DESCR Attribute:
Datasets consists of 1,797 images that are 8x8 pixels in size.Each image is a handwritten digit in grayscale.

Representing images as array of 8x8 matrix
Each element of this array is an image that is represented by an 8x8 matrix of numerical values that correspond to a grayscale from white, with a value of 0, to black, with the value 15.

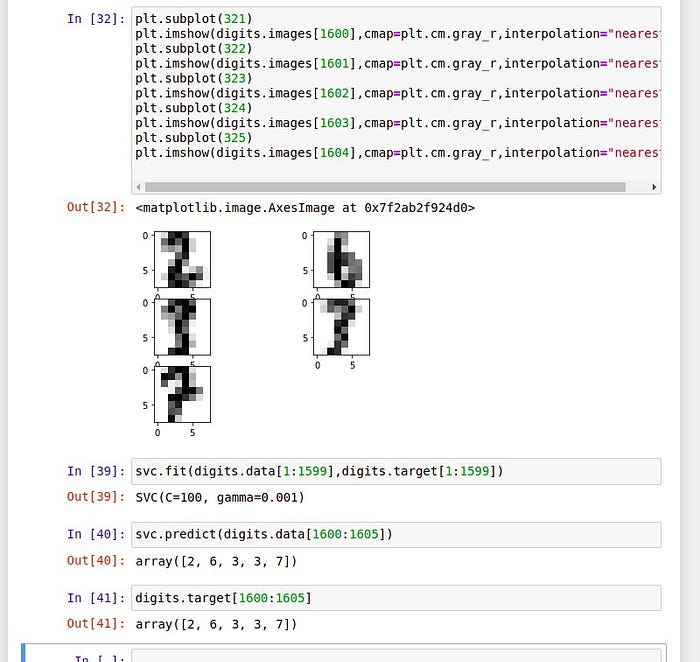
Visualization of images:
We can visually check the contents of this result using the matplotlib library.The numerical values represented by images, i.e. , the targets,are contained in the digit.targets array. It was reported that the datasets is training set consisting of 1,797 images.You con determine if that is true.

I have used 3 different variation in datasets to check the accuracy.To define a predictive model,one must instruct it with a training set,which is a set of data in which you already know the belonging class. Given the large quantity of elements contained in the digits datasets, we will certainly obtain a very effective model that is capable of recognizing with good certainty the hand written number.
This dataset contains 1,797 elements and so you can consider the first 1791 as a training set and will use the last six as a validation set.
First variation in prediction model

Second variation in prediction model:

Third variation in prediction model:
Conclusion:
As we can see it not necessary that we will always get accurate result. We tried each case for different range of training and validation sets and found little variation in digits in grayscale i.e result would vary with training set and validation set.
